|
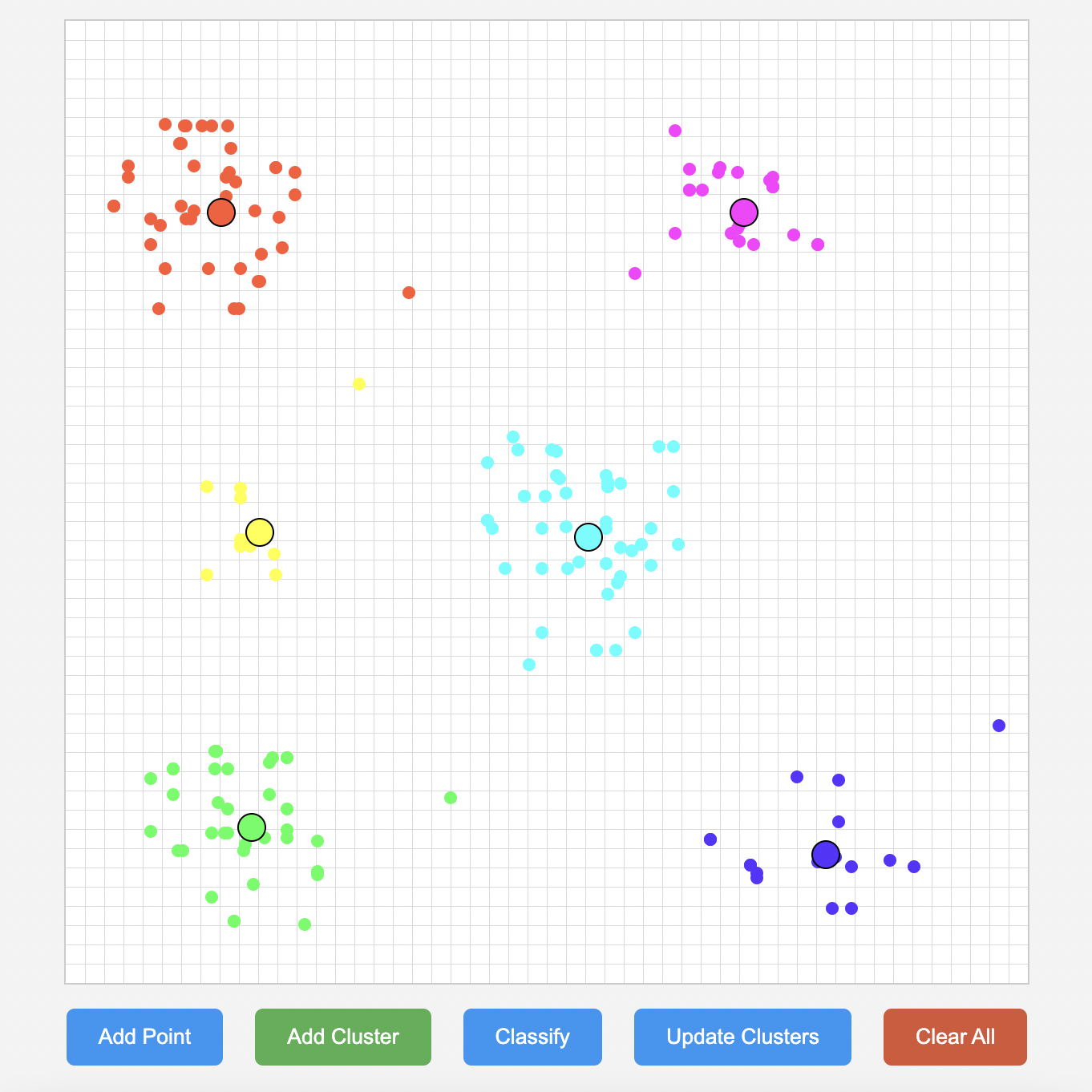
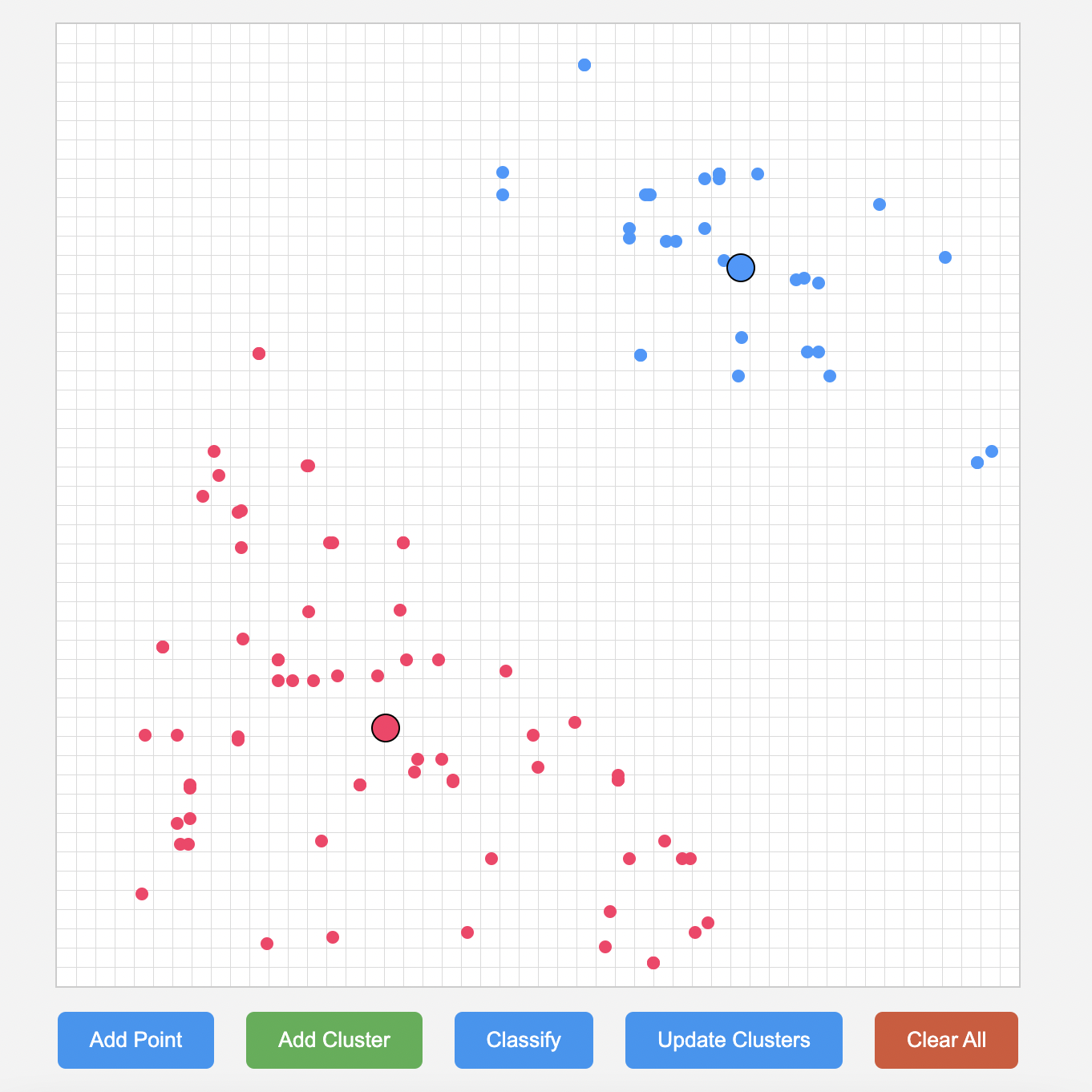
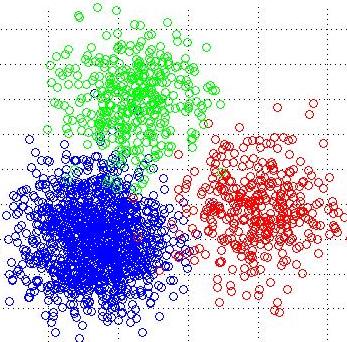
K-Means Visualizer |
- K-Means is a clustering algorithm that organizes data into K distinct groups based on similarity without predefined labels.
- The goal of this simulation is to offer immediate visual feedback on how the algorithm partitions data points into clusters, aiding in understanding its iterative nature.
Screenshots: